Unsupervised Image Classification Algorithm
Introduction
Supervised classification requires knowledge of the area of interest. If this knowledge is insufficiently available, or the classes of interest have not yet been defined, an unsupervised classification can be made. In an unsupervised classification, clustering algorithms are used to partition the feature space into a number of clusters.
Explanation
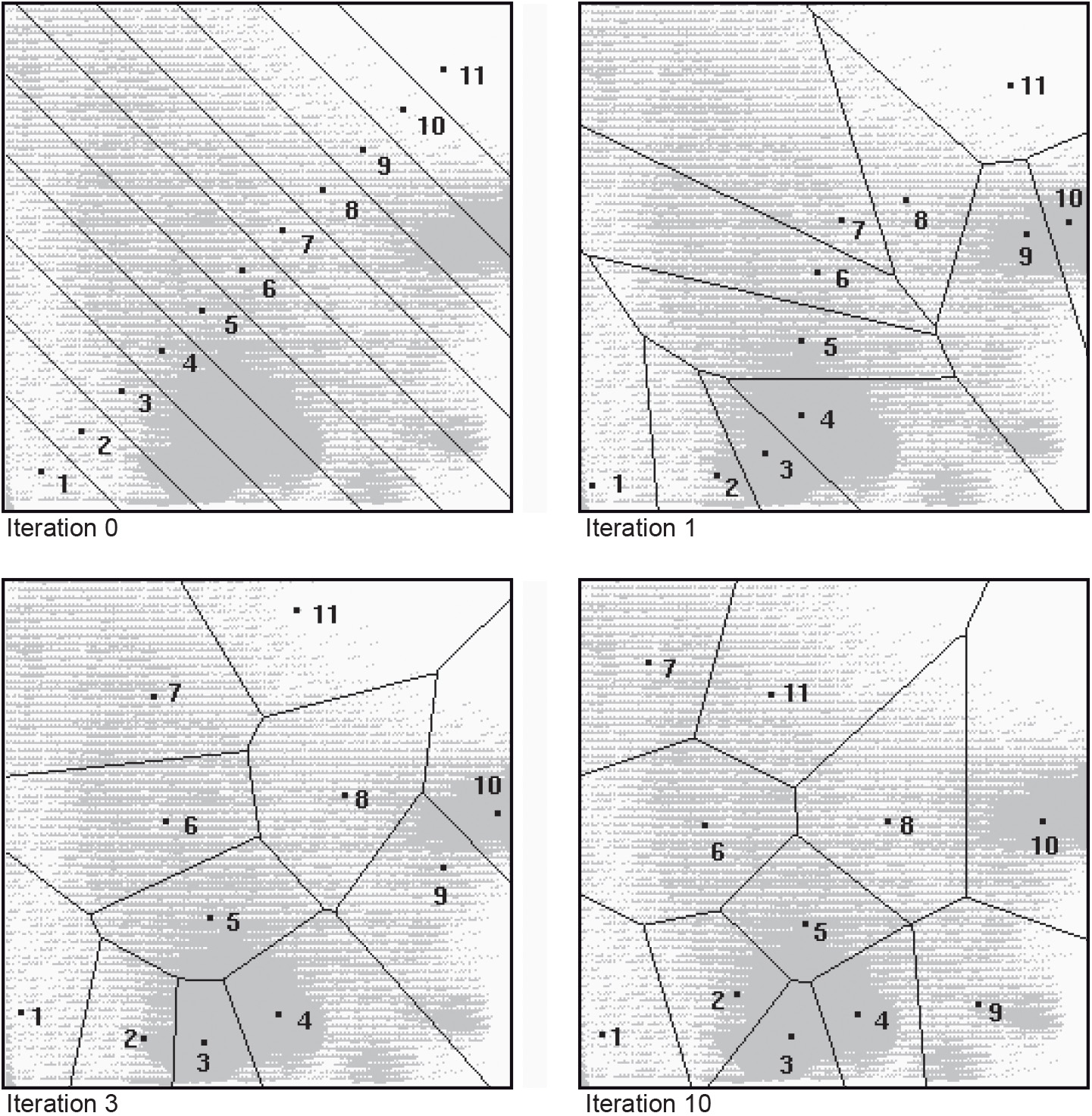
Several methods of unsupervised classification exist, their main purpose being to produce spectral groupings based on certain spectral similarities. In one of the most common approaches, the user has to define the maximum number of clusters in a data set. Based on this, the computer locates arbitrary mean vectors as the centre points of the clusters. Each pixel is then assigned to a cluster by the minimum distance to cluster centroid decision rule. Once all the cells have been labelled, recalculation of the cluster centre takes place and the process is repeated until the proper cluster centres are found and the cells are labelled accordingly.
The iteration stops when the cluster centres no longer change. However, for any iteration, clusters with less than a specified number of cells are eliminated. Once the clustering is finished, analysis of the closeness or separability of the clusters takes place by means of inter-cluster distance or divergence measures.
Merging of clusters needs to be done to reduce the number of unnecessary subdivisions in the data set. This is be done using a pre-specified threshold value. The user has to define the maximum number of clusters/classes, the distance between two cluster centres, the radius of a cluster, and the minimum number of cells as a threshold for cluster elimination. Analysis of the cluster compactness around its centre point is done by means of the user-defined standard deviation for each spectral band. If a cluster is elongated, separation of the cluster will be done perpendicularly to the spectral axis of elongation.
Analysis of closeness of the clusters is carried out by measuring the distance between the two cluster centres. If the distance between two cluster centres is less than the pre-specified threshold, merging of the clusters takes place. The clusters that result after the last iteration are described by their statistics. Figure 1 shows the results of a clustering algorithm on a data set. Note that the cluster centres coincide with the high density areas in the feature space.
Similarly to the supervised approach, the derived cluster statistics are then used to classify the complete image using a selected classification algorithm.
Outgoing relations
- Unsupervised Image Classification Algorithm is a kind of Classification Algorithm
- Unsupervised Image Classification Algorithm is a kind of Pixel based classifcation
Incoming relations
- Unsupervised change detection is related to Unsupervised Image Classification Algorithm