Resources - Jp
Introduction
This concept is created for placing the resources for exam.
Explanation
ABM - fundamental (agent, env, time)
ABM 2 - Complex system and methods to design ABM
- Lecture slide with note (methods to design ABM)
- My note about complex system
- Team based learning with note
ABM 3 - Verification and Validation
ABM 4 - ODD protocol
- Lecture slides with note
- My note about agent-agent and agent-env interaction
- Agent-agent interactions: include sharing information, adapting behaviors based on others' action and influencing each other's decision-making processes.
If interaction is sharing info, the information will be stored. So Interactions are not always lead to behaviour change in the agent. - Agent-environment interaction:
Env affect agent's behavior
- static env: Agent retrieve the distance to exit value from raster env to decide which cells that they will move
- dynamic env: smoke develop and trap the the agents so agents need to change their behavior
Agent affect environment
- Sheep eat grass, agent build the house - Environment-environment interaction:
- fire develop, smoke also develop
- grass and ground water
- Agent-agent interactions: include sharing information, adapting behaviors based on others' action and influencing each other's decision-making processes.
- Team based learning with note (interaction)
- Team based learning with note (ODD)
ABM 5 - Integration with ML
Simulation type
- Abstract: simplified agent behavior (doesn't take all behavior of agent into account), simplified environment (doesn't represent real-world env)
- Experimental: controlled setting, have some real characteristics (agent), test hypothesis
- Historical: simulate past events based on historical data
- Empirical: rely on data collected from real-world observations
-----------------------------------------------------------------------------------
ML - E(S)DA
ML - Clustering
- My note about clustering
- Additional material for kmeans clustering
- K-Means Limitation
- Centroid Initialization -> different centroid initialization can lead to different results because K-Means relies on distance calculations to assign data points to clusters and update centroids.
- Curse of dimensionality
- risk of overfitting (model fits the training data very well)
- difference in distance between observations become less and it is harder for model to distinguish/cluster the observations
- increase computational resource
- Solving Curse of dimensionality -> reducing the dimensionality (features)
- feature selection - select subsets of original features
- feature extraction - create new set of features by transforming original features
- Principal Component Analysis (PCA) - reducing the number of dimensions (features) while retaining most of the important information
ML - ANN & SOM
- Lecture slides with note
- Deep learning vs Neural network
- Main difference is Deep learning can automatically learn and extract features from raw data
- SOM vs K-Means
- SOM -> consider neighbourhood (ensure that not only the Best Matching Unit (BMU) but also its neighboring neurons are updated during the training process), show the smooth transition between cluster, SOM is particularly useful for visualizing high-dimensional data and preserving topological relationships
ML - DT & RF
- My note about DT and RF
- Additional note on RF
- Bias and variance
Bias Variance 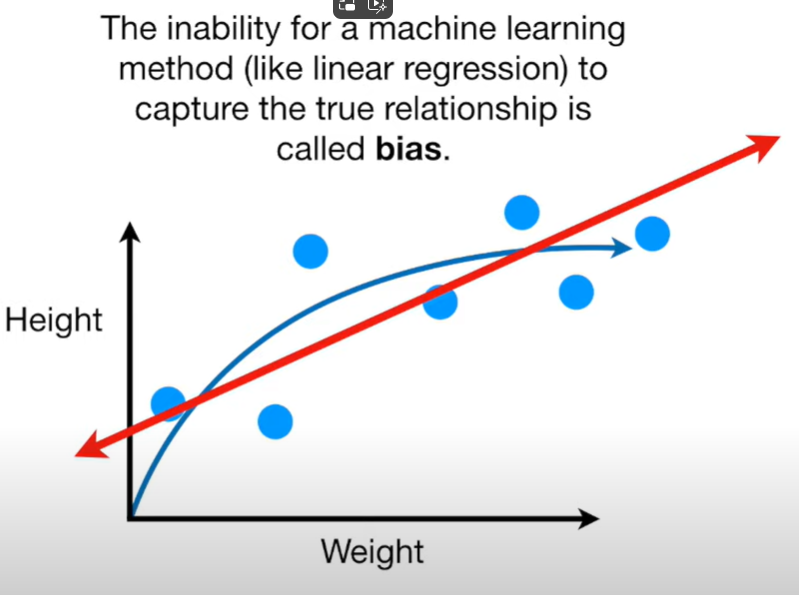
bias 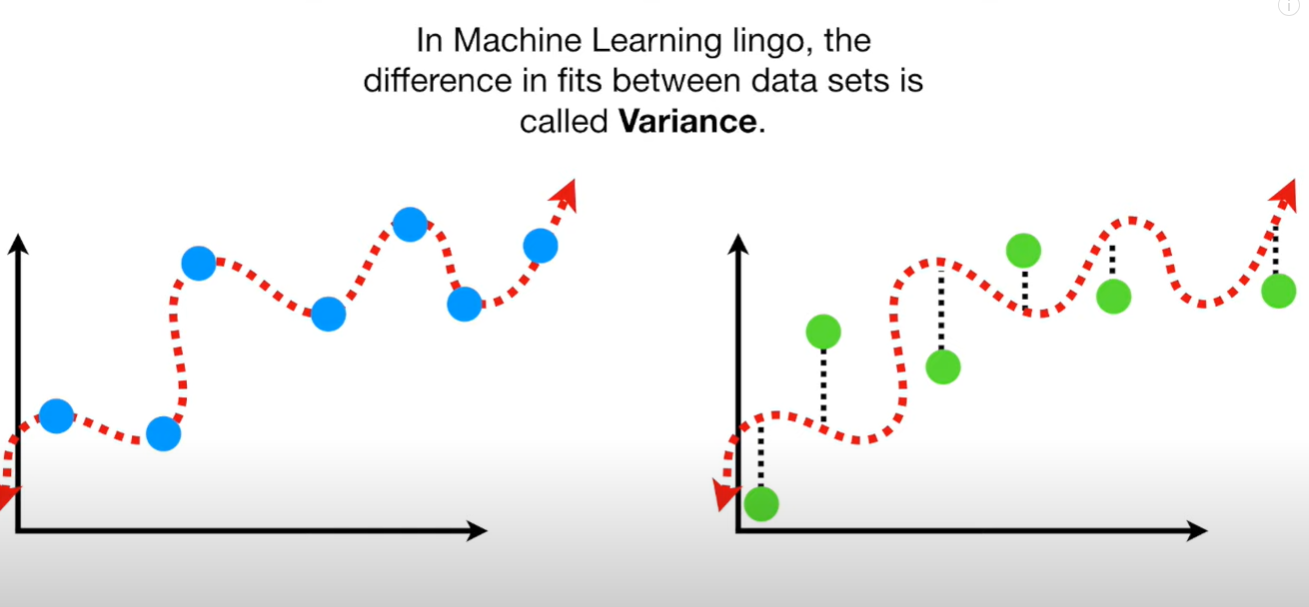
variance
- Team based learning