Accuracy differences
Introduction
Differences in accuracy involve issues relating to positional error, attribute accuracy and temporal accuracy and are clearly relevant in any combination of data sets, which may themselves have varying levels of accuracy.
Explanation
Images come at a certain resolution, and printed maps at a certain scale. This typically results in differences of resolution of acquired data sets, all the more since map features are sometimes intentionally displaced or in another way generalized to improve readability of the map. For instance, the course of a river will only be approximated roughly on a small-scale map, and a village on its northern bank should be depicted north of the river, even if this means it has to be displaced on the map a little bit. The small scale causes an accuracy error. If we want to combine a digitized version of that map with a digitized version of a large-scale map, we must be aware that features may not be where they seem to be. Analogous examples can be given for images of different resolutions.
There can be good reasons for having data sets at different scales. A good example is found in mapping organizations. European organizations maintain a single source database that contains the base data. This database is essentially scale-less and contains all data required for even the largest scale map to be produced. For each map scale that the mapping organization produces, they derive a separate database from the foundation data. Such a derived database may be called a cartographic database since the data stored are elements to be printed on a map, including, for instance, data on where to place name tags and what colour to give them. This may mean the organization has one database for the larger scale ranges (1:5000–1:10,000) and other databases for the smaller scale ranges; they maintain a multi-scale data environment.
More recent research has addressed the development of one database incorporating both larger and smaller scale ranges. Here we identify two main approaches: one approach to realize this is to store multiple representations of the same object in a multiple representation database. The database must keep track of links between different representations for the same object and must also provide support for decisions as to which representations to use in which situation. Another approach is to maintain one database for the larger scale ranges and derive representations for the smaller scale ranges on the fly. That means the data have to be generalized in real time. A combination of both approaches is to store multiple object representations for time-consuming generalization processes, which sometimes cannot be done fully automatically, and derive representations for the smaller scales in real time on the fly for rapid generalization processes.
Examples
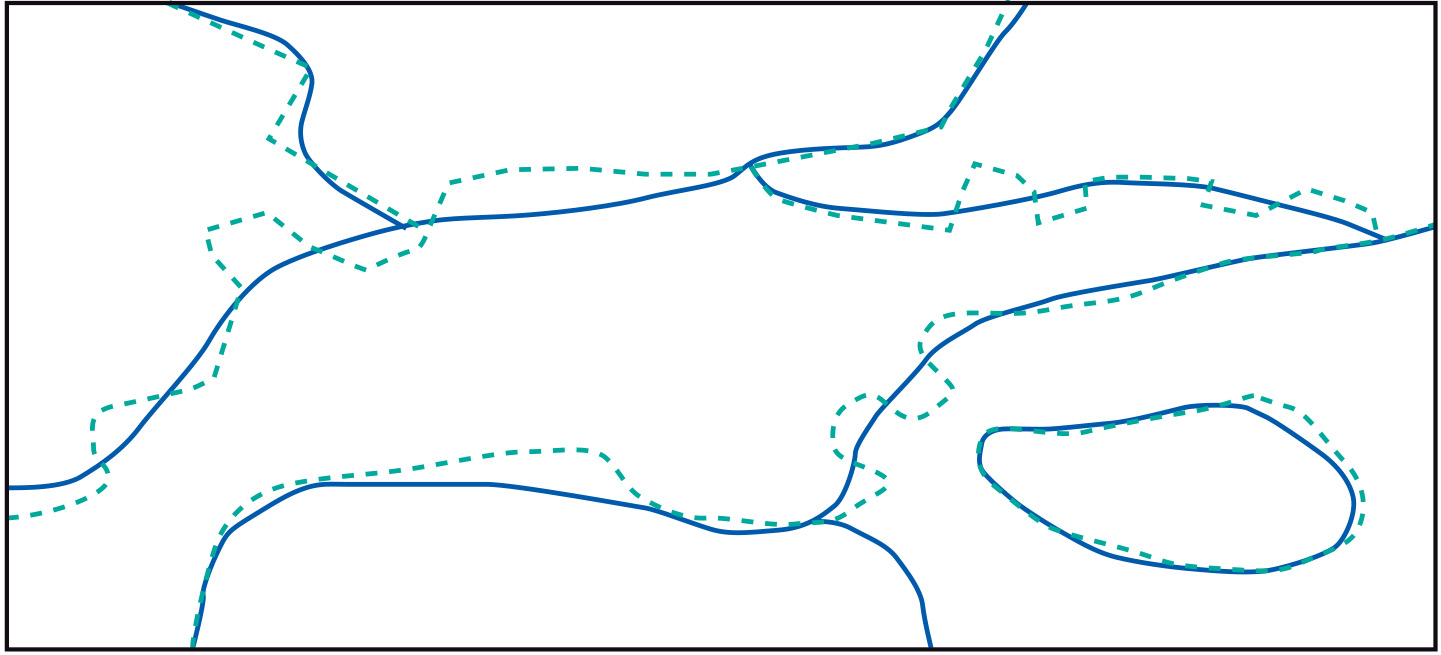
In the figure above, the polygons of two digitized maps at different scales are overlaid. Owing to scale differences in the sources, the resulting polygons do not perfectly coincide, and polygon boundaries cross each other. This causes small, artefact polygons in the overlay that are known as sliver polygons. If the map scales differ significantly, the polygon boundaries of the large-scale map should probably take priority, but when the differences are slight, we need interactive techniques to resolve any issues.
Learning outcomes
-
14 - Data quality: data handling
Identify the impact of Geo-information handling on data quality (level 1).
Prior knowledge
Outgoing relations
- Accuracy differences is part of Combining data from multiple sources