Random Forest
Random forest (RF) is machine learning algorithm which combines the output of multiple decision trees to reach a single result.
Introduction
Leo Breiman continued working on DT and around the year 2000 he
found and demonstrated that regression results and classification
accuracy can be improved by using ensembles of trees where each tree
grown in a “random” fashion.
Advantages
- No purning needed
- High Accuracy
- Provides variable importance
- No overfitting, not very sensitive to outliers
- Fast and easy to implement
- Easily paralellized
Disadvantages
- Cannot predict beyond range of input parameters
- Smoothing extreme values (underestimate high values, overestimate low values)
- More difficult to visualize or interpret
Explanation
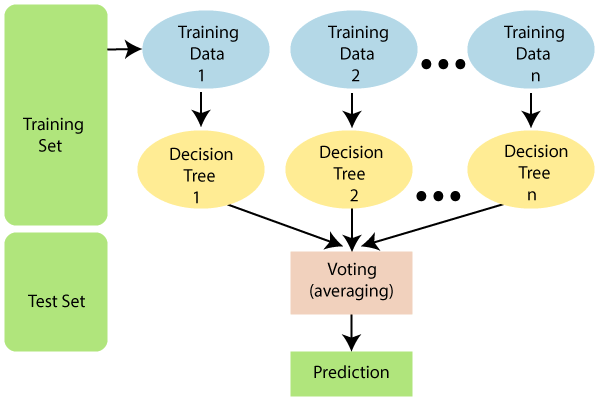
Random forest algorithm:
- Input data: N training cases each with M variables
- n out of N samples are choosen with replacement (bootstrapping)
- Rest of the samples to estimate the error of the tree (out of bag)
- m << M variables are used to determine the decision at a node of the tree
- Each tree is fully grown and not purned
- Output of the ensemble: aggregation of the outputs of the trees
Response variables:
- Majority, for classification
- Average, for regression
Outgoing relations
- Random Forest is a kind of Supervised Learning
- Random Forest is part of Machine Learning
Incoming relations
- Decision Tree is part of Random Forest