Digital Image Classification
Introduction
The process of visual image interpretation has been explained in visual image interpretation. In this process, human vision plays a crucial role in extracting information from images. Although computers may be used for visualization and digitization, the interpretation itself is done by the human operator.
This section introduces digital image classification. In this process, the human operator instructs the computer to perform an interpretation according to certain conditions, which are defined by the operator. Image classification is one of the techniques in the domain of digital image interpretation. Other techniques include automatic object recognition (for example, road detection) and scene reconstruction (for example, generation of 3D object models). Image classification is the most commonly applied technique in ITC’s fields of interest.
Explanation
Image classification is applied in many regional-scale projects. In Asia, the Asian Association of Remote Sensing (AARS) is generating various sets of land cover data based on supervised and unsupervised classification of multispectral satellite data. In the Africover project (an FAO initiative), techniques for digital image classification are being used to establish a pan-African land cover data set. The European Commission requires national governments to verify the claims of farmers related to crop subsidies. To meet these requirements, national governments employ companies to make an initial inventory, using image classification techniques, which is followed later by field checks.
Image classification is based on the different spectral characteristics of different materials. The concepts of image space and feature space, where image classification are explained below. There is an overview of the classification process (see Figure 1), the steps involved and the choices to be made. The results of image classifications need to be validated to assess their accuracy. The problems of standard classification and introduces object-oriented classification is also discussed.
Image classification process
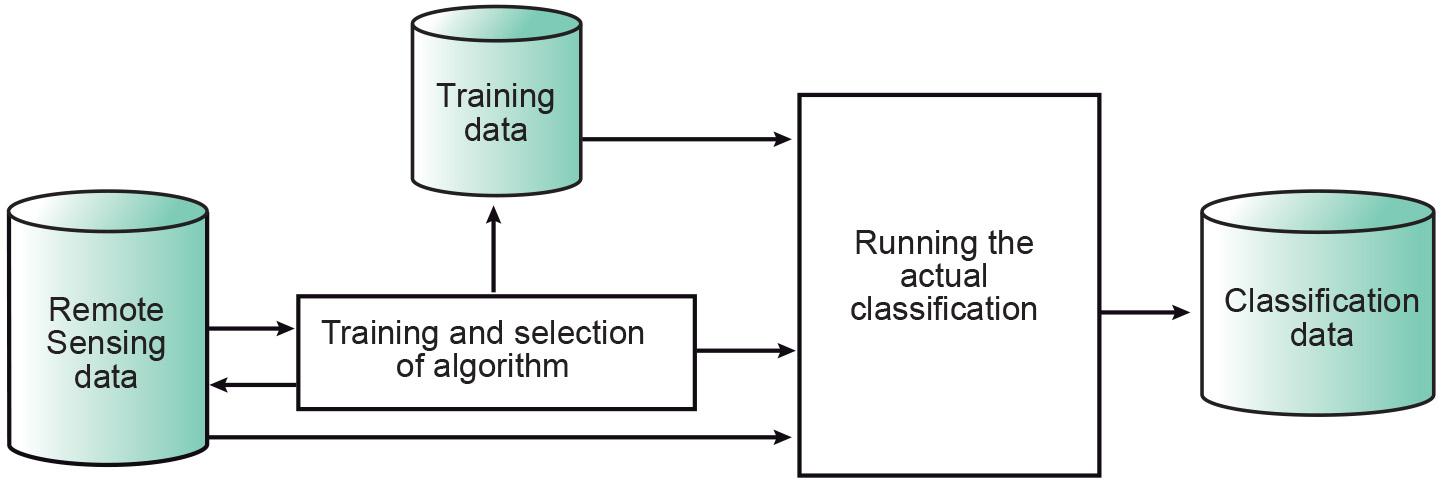
The process of image classification typically involves five steps:
- Selection and preparation of the RS images. Depending on the land cover types or whatever needs to be classified, the most appropriate sensor, the most appropriate date(s) of acquisition and the most appropriate wavelength bands should be selected.
-
Definition of the clusters in the feature space. Here two approaches are possible: supervised classification and unsupervised classification. In a supervised classification, the operator defines the clusters during the training process; in an unsupervised classification, a clustering algorithm automatically finds and defines the number of clusters in the feature space.
-
Selection of the classification algorithm. Once the spectral classes have been defined in the feature space, the operator needs to decide on how the pixels (based on their feature vectors) are to be assigned to the classes. The assignment can be based on different criteria.
-
Running the actual classification. Once the training data have been established and the classifier algorithm selected, the actual classification can be carried out. This means that, based on its DNs, each “multi-band pixel” (cell) in the image is assigned to one of the predefined classes (Figure 2).
-
Validation of the result. Once the classified image has been produced its quality is assessed by comparing it to reference data (ground truth). This requires selection of a sampling technique, generation of an error matrix, and the calculation of error parameters.

Each of the steps above are elaborated on in the next subsections. For simplicity and ease of visualization, most examples deal with a two-dimensional situation (two bands), although in principle image classification can be carried out on any n-dimensional data set. Visual image interpretation, however, limits itself to an image that is composed of a maximum of three bands.
Preparation for image classification
Image classification serves a specific goal: converting RS images to thematic data. In the context of a particular application, one is rather more interested in the thematic characteristics of an area (a GRC) than in its reflection values. Thematic characteristics such as land cover, land use, soil type or mineral type can be used for further analysis and input into models. In addition, image classification can also be considered as data reduction: the n multispectral bands result in a single-band image file.
With the particular application in mind, the information classes of interest need to be defined. The possibilities for the classification of land cover types depend on the date an image was acquired. This not only holds for crops, which have a certain growth cycle, but also for other applications such as snow cover or illumination by the Sun. In some situations, a multi-temporal data set is required. A non-trivial point is that the required images should be available at the required moment. Limited image acquisition and cloud cover may force one to make use of a less-optimal data set.
Before starting to work with the acquired data, a selection of the available spectral bands may be made. Reasons for not using all available bands (for example all seven bands of Landsat-5 TM) lie in the problem of band correlation and, sometimes, in limitations of hardware and software. Band correlation occurs when the spectral reflection is similar for two bands. The correlation between the green and red wavelength bands for vegetation is an example: a low reflectance in green correlates with a low reflectance in red. For classification purposes, correlated bands give redundant information and might disturb the classification process.
Outgoing relations
- Digital Image Classification is a kind of Image analysis
Incoming relations
- Object based classifcation is a kind of Digital Image Classification
- Pixel based classifcation is a kind of Digital Image Classification
- Class Definition is part of Digital Image Classification
- Classification Algorithm is part of Digital Image Classification
- Training is part of Digital Image Classification
- Validation of results is part of Digital Image Classification
- Classification-based change detection is related to Digital Image Classification