6 - Data retrieval and queries
Explain the basic concepts of data retrieval (attribute and spatial queries) and formulate queries to make a selection on attributes and geospatial data from a spatial database.
Concepts
-
Data attribute
An attribute is a named field of a tuple in a relation (or table). An attribute’s domain is a (possibly infinite) set of atomic values such as, for example, the set of integer number values or the set of real number values.
-
Spatial database
Spatial databases, also known as geo-databases, are implemented directly on existing DBMSs using extension software to allow them to handle spatial objects.
-
Relation
In relational data models, a database is viewed as a collection of relations, also commonly referred to as tables. A table or relation is itself a collection of tuples (or records). In fact, each table is a collection of tuples that are similarly shaped. By this, we mean that a tuple has a fixed number of named fields (also known as attributes).
-
Querying a spatial database with SQL
The most common operator for defining queries in a relational database is the language SQL, which stands for Structured Query Language.
-
Selection by attributes
Tuple selection works like a filter: it allows tuples that meet the selection condition to pass and disallows tuples that do not meet the condition. The operator is given some input relation, as well as a selection condition about tuples in the input relation. A selection condition is a truth statement about a tuple’s attribute values, such as AreaSize > 1000. For some tuples in Parcel, this statement will be true and for others it will be false. Tuple selection on the Parcel relation with this condition will result in a set of Parcel tuples for which the condition is true.
-
Selection of records
Tuple selection works like a filter: it allows tuples that meet the selection condition to pass and disallows tuples that do not meet the condition. The operator is given some input relation, as well as a selection condition about tuples in the input relation. A selection condition is a truth statement about a tuple’s attribute values, such as AreaSize > 1000. For some tuples in Parcel, this statement will be true and for others it will be false. Tuple selection on the Parcel relation with this condition will result in a set of Parcel tuples for which the condition is true.
Queries like the tuple selection and attribute projection do not create stored tables in the database. This is why the result tables have no name: they are virtual tables. The result of a query is a table that is shown to the user who executed the query. Whenever the user closes her/his view on the query result, that result is lost. The SQL code for the query is, however, stored for future use. The user can re-execute the query again to obtain a view on the result once more.
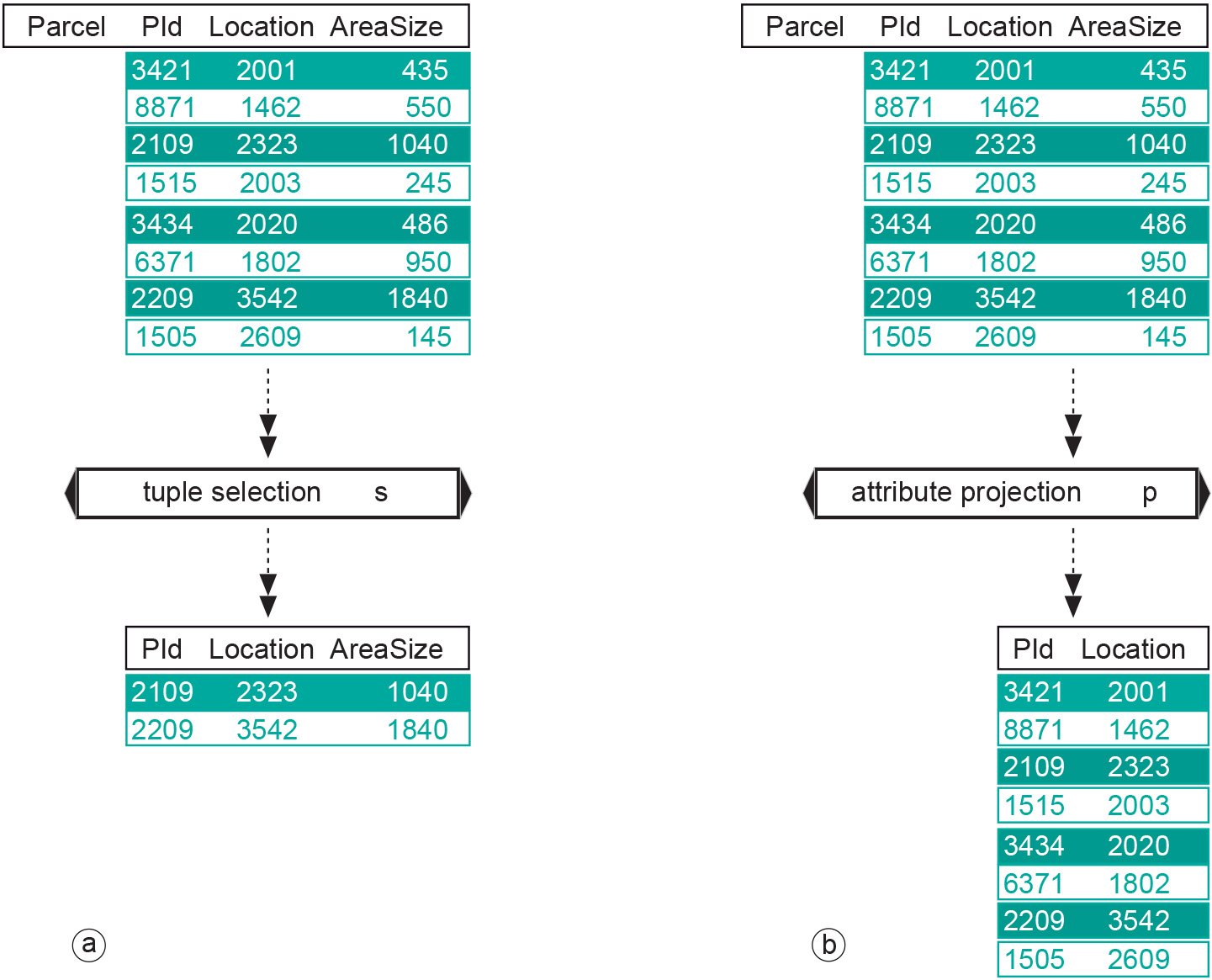
Figure: The two unary query operators: (a) tuple selection has a single table as input and produces another table with less tuples. Here, the condition was that AreaSize must be over 1000; (b) attribute projection has a single table as input and produces another table with fewer attributes. Here, the projection is onto the attributes PId and Location. -
Tuple
Tuples (or records) are individual entries in a relation (or table). All tuples in the same relation have the same named fields. In a diagram, such as in Figure 1 above, relations can be displayed as data in tabular form, as the relations provided in the figure demonstrate. The PrivatePerson table has three tuples; the Surname attribute value for the first tuple shown is “Garcia.” Tuples can be specifically queried using tuple selection.
-
Data integration
Combination of Earth observation data with other types of geospatial data is highly recommended since existing information can be essential for improving the interpretation of remote sensing data. The automatic classification of agricultural crops from multispectral image data is such an example. Pixel-by-pixel classification usually gives many errors, owing to sensor noise and field heterogeneity. However, if parcel boundaries are known from a GIS database, one can classify all pixels within a field as a group, which reduces the number of misclassifications enormously, provided, of course, that the group as a whole is correctly classified.
Data can be integrated in an almost infinite number of ways. Results from data integration can, again, be combined with other geospatial data to produce yet other new information, and so on.