5 - Data management: relational database and DBMS
Describe and explain the structure and components of a relational data model and a relational database (level 1 and 2). Describe and explain what a Database Management System (DBMS) is and how it links to a GIS.
Concepts
-
Data attribute
An attribute is a named field of a tuple in a relation (or table). An attribute’s domain is a (possibly infinite) set of atomic values such as, for example, the set of integer number values or the set of real number values.
-
Relation
In relational data models, a database is viewed as a collection of relations, also commonly referred to as tables. A table or relation is itself a collection of tuples (or records). In fact, each table is a collection of tuples that are similarly shaped. By this, we mean that a tuple has a fixed number of named fields (also known as attributes).
-
Logical expression
Atomic conditions can be combined into composite conditions using logical connectives. The most important ones are AND, OR, NOT and the bracket pair (…). If we write a composite condition such as Area < 400,000 AND Land Use = 80, we can use it to select areas for which both atomic conditions hold true. This is the meaning of the AND connective. If we had written Area < 400,000 OR Land Use = 80 instead, the condition would have selected areas for which either condition holds, so effectively those with an area size less than 400,000, but also those with land use class 80. (Included, of course, will be areas for which both conditions hold.)
The NOT connective can be used to negate a condition. For instance, the condition NOT (Land Use = 80) would select all areas with a different land use class than 80. (Clearly, the same selection can be obtained by writing Land Use <> 80 but this is not the point.) Finally, brackets can be applied to force grouping amongst atomic parts of a composite condition . For instance, the condition (Area < 30,000 AND Land Use = 70) OR (Area < 400,000 AND Land Use = 80) will select areas of class 70 less than 30,000 in size, as well as class 80 areas less than 400,000 in size.
-
Querying a spatial database with SQL
The most common operator for defining queries in a relational database is the language SQL, which stands for Structured Query Language.
-
Selection by attributes
Tuple selection works like a filter: it allows tuples that meet the selection condition to pass and disallows tuples that do not meet the condition. The operator is given some input relation, as well as a selection condition about tuples in the input relation. A selection condition is a truth statement about a tuple’s attribute values, such as AreaSize > 1000. For some tuples in Parcel, this statement will be true and for others it will be false. Tuple selection on the Parcel relation with this condition will result in a set of Parcel tuples for which the condition is true.
-
Selection condition
A selection condition is a truth statement about a tuple’s attribute values, such as AreaSize > 1000. For some tuples in Parcel, this statement will be true and for others it will be false. Tuple selection on the Parcel relation with this condition will result in a set of Parcel tuples for which the condition is true.
-
Attribute projection
A second operator, called attribute projection, requires a list of attributes, all of which should be attributes of the schema of the input relation. The output relation of this operator has as its schema only the list of attributes given, so we say that the operator projects onto these attributes. Contrary to the first operator, which produces fewer tuples, this operator produces fewer attributes compared to the input relation.
Attribute projection works like a tuple formatter: it passes through all tuples of the input, and reshapes each of them in the same way.
Queries like the tuple selection and attribute projection do not create stored tables in the database. This is why the result tables have no name: they are virtual tables. The result of a query is a table that is shown to the user who executed the query. Whenever the user closes her/his view on the query result, that result is lost. The SQL code for the query is, however, stored for future use. The user can re-execute the query again to obtain a view on the result once more.
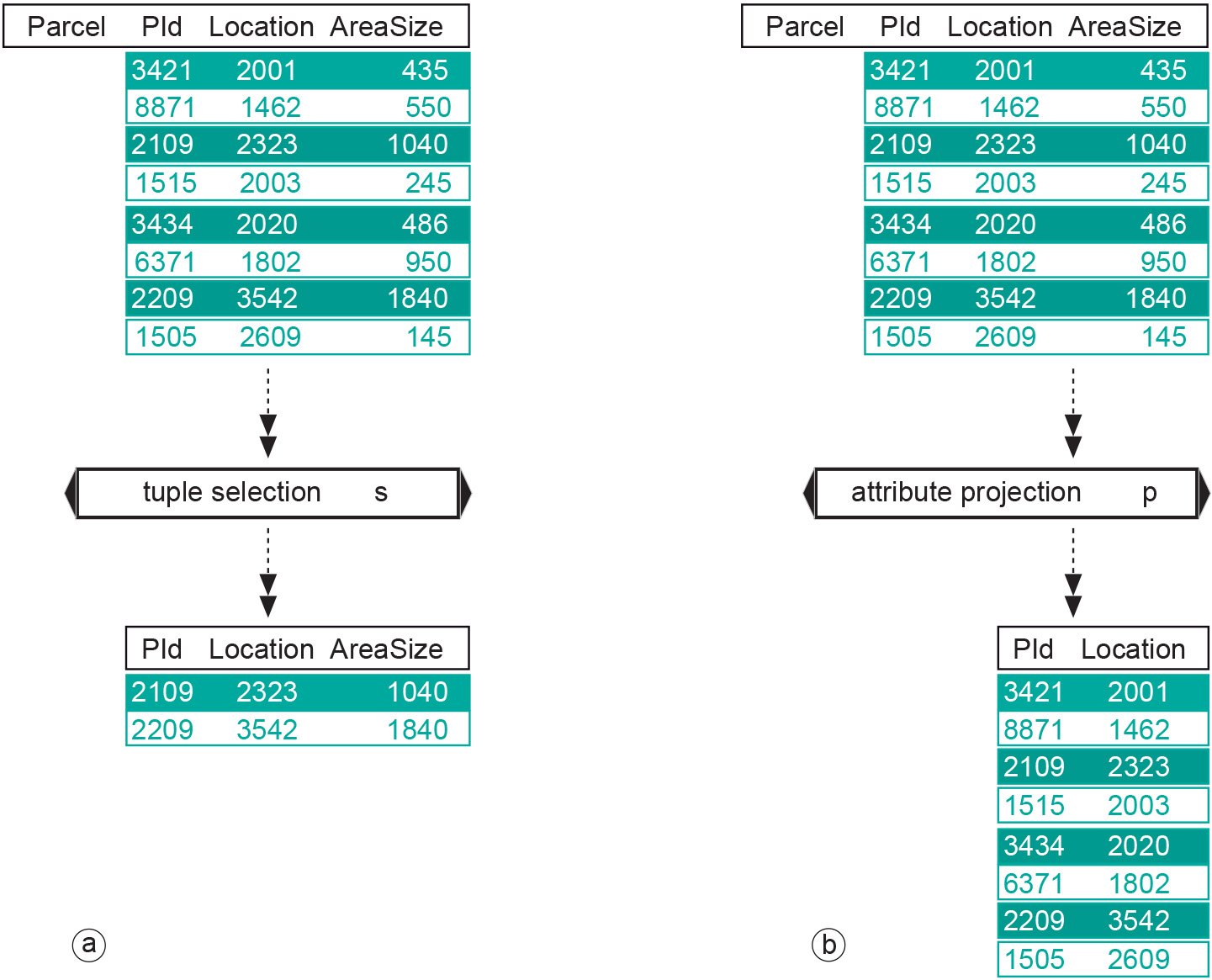
Figure : The two unary query operators: (a) tuple selection has a single table as input and produces another table with less tuples. Here, the condition was that AreaSize must be over 1000; (b) attribute projection has a single table as input and produces another table with fewer attributes. Here, the projection is onto the attributes PId and Location. -
Selection of records
Tuple selection works like a filter: it allows tuples that meet the selection condition to pass and disallows tuples that do not meet the condition. The operator is given some input relation, as well as a selection condition about tuples in the input relation. A selection condition is a truth statement about a tuple’s attribute values, such as AreaSize > 1000. For some tuples in Parcel, this statement will be true and for others it will be false. Tuple selection on the Parcel relation with this condition will result in a set of Parcel tuples for which the condition is true.
Queries like the tuple selection and attribute projection do not create stored tables in the database. This is why the result tables have no name: they are virtual tables. The result of a query is a table that is shown to the user who executed the query. Whenever the user closes her/his view on the query result, that result is lost. The SQL code for the query is, however, stored for future use. The user can re-execute the query again to obtain a view on the result once more.
Figure: The two unary query operators: (a) tuple selection has a single table as input and produces another table with less tuples. Here, the condition was that AreaSize must be over 1000; (b) attribute projection has a single table as input and produces another table with fewer attributes. Here, the projection is onto the attributes PId and Location. -
Tuple
Tuples (or records) are individual entries in a relation (or table). All tuples in the same relation have the same named fields. In a diagram, such as in Figure 1 above, relations can be displayed as data in tabular form, as the relations provided in the figure demonstrate. The PrivatePerson table has three tuples; the Surname attribute value for the first tuple shown is “Garcia.” Tuples can be specifically queried using tuple selection.
-
Keys
database systems are particularly good at storing large quantities of data. (Our example
database is not even small, it is tiny!) The DBMS must support rapid searching
among many tuples. This is why relational data models use the notion of a key. In
other words, if we have a value for each of the key attributes we are guaranteed to
find no more than one tuple in the table with that combination of values; it remains
possible that there is no tuple for the given combination. In our example database, the
set TaxId, Surname is a key of the relation PrivatePerson: if we know both a TaxId and
a Surname value, we will find at most one tuple with that combination of values.
Every relation has a key, though possibly it is the combination of all attributes. Such
a large key is, however, not handy because we must provide a value for each of its
attributes when we search for tuples. Clearly, we want a key to have as few as possible
attributes: the fewer, the better.
A key of a relation comprises one or more attributes. A value for these attributes
uniquely identifies a tuple.
If a key has just one attribute, it obviously cannot have less attributes. Some keys have two attributes; an example is the key Plot, Owner of relation TitleDeed. We need both attributes because there can be many title deeds for a single plot (in the case of
plots that are sold often), but also many title deeds for a single person (say, in the
case of wealthy persons). When we provide a value for a key, we can look up the
corresponding tuple in the table (if such a tuple exists). A tuple can refer to another
tuple by storing that other tuple’s key value. For instance, a TitleDeed tuple refers to
a Parcel tuple by including that tuple’s key value. The TitleDeed table has a special
attribute Plot for storing such values. The Plot attribute is called a foreign key because
foreign key it refers to the primary key (Pid) of another relation (Parcel). This is illustrated in the figure below.
Figure: The table TitleDeed has a foreign key in its attribute Plot. This attribute refers to key values of the Parcel relation, as indicated for two TitleDeed tuples. The table TitleDeed actually has a second foreign key in the attribute Owner, which refers to PrivatePerson tuples. Two tuples of the same relation instance can have identical foreign key values: for
instance, two TitleDeed tuples may refer to the same Parcel tuple. A foreign key is,
therefore, not a key of the relation in which it appears, despite its name! A foreign key
must have as many attributes as the primary key that it refers to.